개요
최근 딥러닝이 발전하면서, 자연어 처리(NLP) 쪽에는 OPT나 LLaMA 같은 모델이 등장했다. 비전-랭귀지(V&L) 쪽에서는 CLIP이나 DALL·E 같은 모델이 등장했다. 이런 대형 모델들은 뛰어난 성능을 보이지만, 전체를 미세 조정하려면 컴퓨트 코스트가 매우 크다는 문제가 있다.
이를 해결하기 위해 LoRA가 등장했다. LoRA는 사전 학습된 모델 가중치는 그대로 두고, 저차원 매트릭스만 학습하는 방법이다. 하지만 최근에는 이미 학습된 LoRA를 여러 개 조합해서 사용하는 방법이 연구되고 있다.
문제는, 기존 방식으로 3개 이상 LoRA를 단순 합치면 생성 퍼포먼스가 떨어질 수 있다는 점이다. 가중치 정규화를 적용해도, 각 LoRA의 유니크한 특성이 사라질 수 있다.

이 논문에서는 훈련된 LoRA들을 동적으로, 효율적으로 조합하면서 각자의 개별 특성을 살리는 방법을 제안한다.
MoLE: Mixture of LoRA Experts

MoLE는 LoRA를 합치는 새로운 방법이다.
- 서로 다르게 학습된 LoRA들의 가중치를 레이어 단위로 조정한다.
- 이 과정을 Hierarchical Weight Control이라고 부른다.
각각의 LoRA를 하나의 '전문가(expert)'로 보고, 각 레이어에서 도메인 목표에 맞게 최적의 조합 가중치를 학습하는 구조다. MoE와 굉장히 흡사하며, 실제로 MoE에서 영감을 받았다.
이렇게 하면 필요한 특성은 강조하고, 덜 중요한 특성은 줄여서, LoRA 특성의 손실 없이 조합할 수 있다.
구조
MoLE는 기본적으로 다음과 같은 흐름을 따른다.
- Transformer 블록을 거친 사전 학습된 모델 출력과
- 훈련된 여러 LoRA들의 출력을 준비한다.
- 각 LoRA의 출력을 연결(concatenation)하고, 정규화(normalization)한다.
- 이를 학습 가능한 게이팅 함수(Gating Function)에 넣는다.
수식으로는 다음과 같이 표현된다.
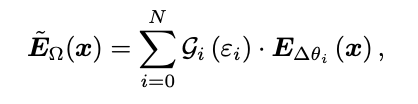
Gi(εi)는 i번째 LoRA의 게이팅 함수 결과값을 의미한다.

위 함수는 i번째 LoRA의 게이팅 함수 출력 값이다.
게이팅 함수는 소프트맥스를 통과하기 때문에 합이 1이 되며, LoRA 출력값에 가중치를 곱하고 더하면 새로운 LoRA 출력값을 다음과같이 얻을 수 있다.

이 과정을 통해 좋은 특성은 강화하고, 덜 중요한 특성은 억제하는 방향으로 LoRA 조합을 최적화할 수 있다.
Gating Balance Loss
이 Loss는 기존에 MoE에서 이미 사용하던 방법인데, 한 expert가 잘하게 되면 계속 모든 관련 학습을 한 expert가 해버리기 때문에 MoE의 장점이 흐려져서 생기는 문제를 해결하기 위해 만든 Loss라고 할 수 있다.
MoLE에서도 동일하게 게이팅 함수가 학습되면서 특정 LoRA에만 가중치를 몰아주는 문제가 발생할 수 있다. 이를 막기 위해 Gating Balance Loss를 사용한다.
공식은 다음과 같다.

여기서 q(i)는 i번째 블록에 대한 평균 게이팅 확률이다.
확률을 곱하게 되면, 편차가 크면 계산값이 작아지고, 각 확률의 편차가 작으면 커지므로, 이 계산값을 최대로 하는 loss를 만든다.
이렇게 되면 벨런스 Loss는 게이팅 분포가 한쪽으로 치우치지 않고, 모든 LoRA에 균형 있게 가중치를 주도록 유도한다.
MoE에서도 다른 방법도 많지만 이런 비슷한 방식을 많이 사용한다.
Domain-Specific Loss
이 Loss는 기존 학습 Loss와 거의 동일하며, 도메인마다 Loss가 다르게 설정된다.
- V&L 도메인에서는 CLIP 기반 Loss를 이용해 비지도 학습을 수행한다.
- NLP 도메인에서는 FLAN-T5 기반 Loss 함수를 따른다.
최종 손실은 Gating Balance Loss와 Domain-Specific Loss의 weighted sum으로 정의된다.

실험
MoLE는 다양한 실험을 통해 기존 LoRA 구성 방식보다 뛰어난 성능을 입증했다.



자세한 수치는 논문 참조
MoLE는 기존 모델과 기존 로라들을 게이팅 함수를 통해 적절한 가중치를 취해서 LoRA를 합치는 모델이다.
날먹이라고 생각할 수도 있지만, 나는 꽤 획기적이라고 봤다. 이미 있던 걸 잘 쓰는 것도 충분히 기술이라고 생각했다.
'Paper' 카테고리의 다른 글
| GPT Understands, Too (0) | 2024.08.12 |
|---|---|
| Improving Language Understanding by Generative Pre-Training (GPT1) (0) | 2024.08.10 |
| LoRA: Low-Rank Adaptation of Large Language Models (0) | 2024.08.10 |